
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 하이브리드 앱
- 카카오톡
- html
- db
- CUSTOM
- spring
- Java
- 비밀번호
- 안드로이드
- mysql
- 인텐트
- CSS
- Oracle
- 강의
- 사용법
- 하이브리드
- ImageView
- hybrid app
- div
- centos7
- 연동
- php
- spring boot
- radiobutton
- SERVLET
- ViewPager
- Android
- 개발 방법론
- Firebase
- Typescript
- Today
- Total
유혁의 개발 스토리
[DB] Oracle 자주쓰는 문자열 함수 본문
1. 문자열 함수
LOWER(char) : char를 소문자로
UPPER(char) : char를 대문자로
INITCAP(char) : char의 첫문자만 대문자 나머지 소문자
ex) SELECT LOWER(ENG_NAME) FROM EMP;
ex) SELECT UPPER(ENG_NAME) FROM EMP;
ex) SELECT INITCAP(ENG_NAME) FROM EMP;

LENGTH(char) : char의 길이
LENGTHB(char) : char의 길이(영문 1, 한글2) - 한글은 캐릭터셋에 따라 3Byte로 인식될 수 있다
ex) SELECT LENGTH(EMP_NO),LENGTH(EMP_NAME) FROM EMP;
ex) SELECT EMP_NO ,LENGTHB(EMP_NO),EMP_NAME,LENGTHB(EMP_NAME),ENG_NAME, LENGTHB(ENG_NAME) FROM EMP;


LPAD(char1,n,char2) : char1의 왼쪽부터 char2를 채운다. n은 연산후 총 문자열 자릿수를 의미한다.
RPAD(char1,n,char2) : LPAD와 비슷 , 오른쪽부터 진행
ex) SELECT EMP_NO, LPAD(EMP_NO, 10, 0), BIRTH, RPAD(BIRTH, 10, 0) FROM EMP;

CONCAT(char1, char2) : char1 char2를 붙인다.
ex) EMP_NAME, ENG_NAME, CONCAT(EMP_NAME, ENG_NAME);

SUBSTR(char, pos, len) : char의 pos번째 문자부터 len길이만큼 잘라서 반환.
ex) SELECT ENG_NAME, SUBSTR(ENG_NAME,2,4) FROM EMP;

INSTR(char1, char2, n) : char1의 문자열 중, n번째부터 시작해서 char2를 찾는다.
ex) SELECT ENG_NAME, INSTR(ENG_NAME, 'o', 4) FROM EMP;

REPLACE(char1,char2,char3) : char1에서 char2를 찾아 char3을 반환한다. LTRIM과 달리 여러번 진행한다.
ex) SELECT ENG_NAME, REPLACE(ENG_NAME, 'o', 'n') FROM EMP;

TRIM(char) : char의 좌측 우측 공백을 제거
ex) SELECT TRIM(' abc ed fghi ') FROM DUAL;

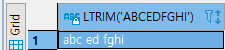
LTRIM(char, pos) : char의 좌측공백제거, pos가 있는경우 pos의 좌측 반복문자 제거
ex) SELECT TRIM(' abc ed fghi ') FROM DUAL;
RTRIM(char, pos) : char의 우측공백제거, pos가 있는경우 pos의 우측 반복문자 제거
ex) SELECT RTRIM(' abc ed fghi ') FROM DUAL;

DECODE(input1, search1 , result1, search2, .. ,default) : input1이 search1인경우, result1을 반환
search1이 아니고 search2인경우, result2를 반환
그외 default 반환
ex) SELECT MANAGER_YN ,DECODE(MANAGER_YN, 'M', '매니저', '일반', '기타') FROM EMP

2. 정리
LOWER(char) : char를 소문자로
UPPER(char) : char을 대문자로
INITCAP(char) : char의 첫문자만 대문자 나머지 소문자
LENGTH(char) : char의 길이
LENGTHB(char) : char의 길이
LPAD(char1,n,char2) : char1의 왼쪽부터 char2를 채운다. n은 연산후 총 문자열 자릿수를 의미한다.
RPAD(char1,n,char2) : LPAD와 비슷 , 오른쪽부터 진행
CONCAT(char1, char2) : char1 char2를 붙인다.
SUBSTR(char, pos,len) : char의 pos번째 문자부터 len길이만큼 잘라서 반환.
INSTR(char1, char2, n) : char1의 문자열 중, n번째부터 시작해서 char2를 찾는다.
REPLACE(char1,char2,char3) : char1에서 char2를 찾아 char3을 반환한다. LTRIM과 달리 여러번 진행한다.
TRIM(char) : char의 좌측 우측 공백을 제거
LTRIM(char, pos) : char의 좌측공백제거, pos가 있는경우 pos의 좌측 반복문자 제거
RTRIM(char, pos) : char의 우측공백제거, pos가 있는경우 pos의 우측 반복문자 제거
DECODE(input1, search1 , result1, search2, .. ,default) : input1이 search1인경우, result1을 반환
search1이 아니고 search2인경우, result2를 반환 그외 default 반환
'DB' 카테고리의 다른 글
| [DB] Oracle 날짜형, 변환형, NULL 함수 (0) | 2021.09.06 |
|---|---|
| [DB] Oracle 자주쓰는 숫자형 함수 (0) | 2021.09.02 |
| [DB] MySQL 계정관리 (0) | 2021.08.24 |
| [DB] DDL - SQL문 (0) | 2021.08.23 |
| [DB] SQL의 종류 (0) | 2021.08.23 |

